驱动层
驱动向内核注册 softirq,里面包含回调函数。驱动收到数据触发中断,kernel读取
1 2 3 4 5 6 7 8 9 10 11 12 13 14 __netif_receive_skb_list_ptype(struct net_device * orig_dev, struct packet_type * pt_prev, struct list_head * head) (/data00/codes/linux/net/core/dev.c:5533 ) __netif_receive_skb_list_core(struct list_head * head, bool pfmemalloc) (/data00/codes/linux/net/core/dev.c:5582 ) __netif_receive_skb_list(struct list_head * head) (/data00/codes/linux/net/core/dev.c:5634 ) netif_receive_skb_list_internal(struct list_head * head) (/data00/codes/linux/net/core/dev.c:5725 ) gro_normal_list(struct napi_struct * napi) (/data00/codes/linux/include/net/gro.h:433 ) gro_normal_list(struct napi_struct * napi) (/data00/codes/linux/include/net/gro.h:429 ) napi_complete_done(struct napi_struct * n, int work_done) (/data00/codes/linux/net/core/dev.c:6065 ) e1000_clean(struct napi_struct * napi, int budget) (/data00/codes/linux/drivers/net/ethernet/intel/e1000/e1000_main.c:3811 ) __napi_poll(struct napi_struct * n, bool * repoll) (/data00/codes/linux/net/core/dev.c:6496 ) napi_poll(struct list_head * repoll, struct napi_struct * n) (/data00/codes/linux/net/core/dev.c:6563 ) net_rx_action(struct softirq_action * h) (/data00/codes/linux/net/core/dev.c:6696 ) __do_softirq() (/data00/codes/linux/kernel/softirq.c:571 ) do_softirq() (/data00/codes/linux/kernel/softirq.c:472 ) do_softirq() (/data00/codes/linux/kernel/softirq.c:459 )
NAPI
基于已有thread_struct封装的新的任务调度库
kernel thread通过thread_struct调度,napi本身封装了thread_struct,内部有kernel thread
驱动初始化代码里创建napi结构,kernel会创建对应的调度上下文,napi 被 kernel调度执行,最后回调驱动代码
为什么NAPI收到第一个包需要关闭中断?
每收到一个包就触发中断会导致极高的CPU占用。NAPI模型采用polling方式避免了大量的中断触发
内核网络层
receive_skb* 有list和非list版本。list可以做GRO合并,根据条件合并多个skb,减少重复处理次数。以list版本继续分析
调用次序
netif_receive_skb_list__netif_receive_skb_list_core__netif_receive_skb_coredeliver_skb
1 2 3 4 5 6 7 8 9 static inline int deliver_skb (struct sk_buff *skb, struct packet_type *pt_prev, struct net_device *orig_dev) { if (unlikely(skb_orphan_frags_rx(skb, GFP_ATOMIC))) return -ENOMEM; refcount_inc(&skb->users); return pt_prev->func(skb, skb->dev, pt_prev, orig_dev); }
IP 层
ipv4 的handler在init阶段注册inet_init
deliver_skb -> ip_rcv ,继续ipv4 流程处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int ip_rcv (struct sk_buff *skb, struct net_device *dev, struct packet_type *pt, struct net_device *orig_dev) { struct net *net = skb = ip_rcv_core(skb, net); if (skb == NULL ) return NET_RX_DROP; return NF_HOOK(NFPROTO_IPV4, NF_INET_PRE_ROUTING, net, NULL , skb, dev, NULL , ip_rcv_finish); }
ip_rcv 逻辑很少,在计数,包检查后交给netfilter hook处理,处理完调用 ip_rcv_finish
skb刚进入IP层第一时间调用 PRE_ROUTING hook
netfilter PRE_ROUTING hook
netfilter hook 执行过程后面会详细讲解
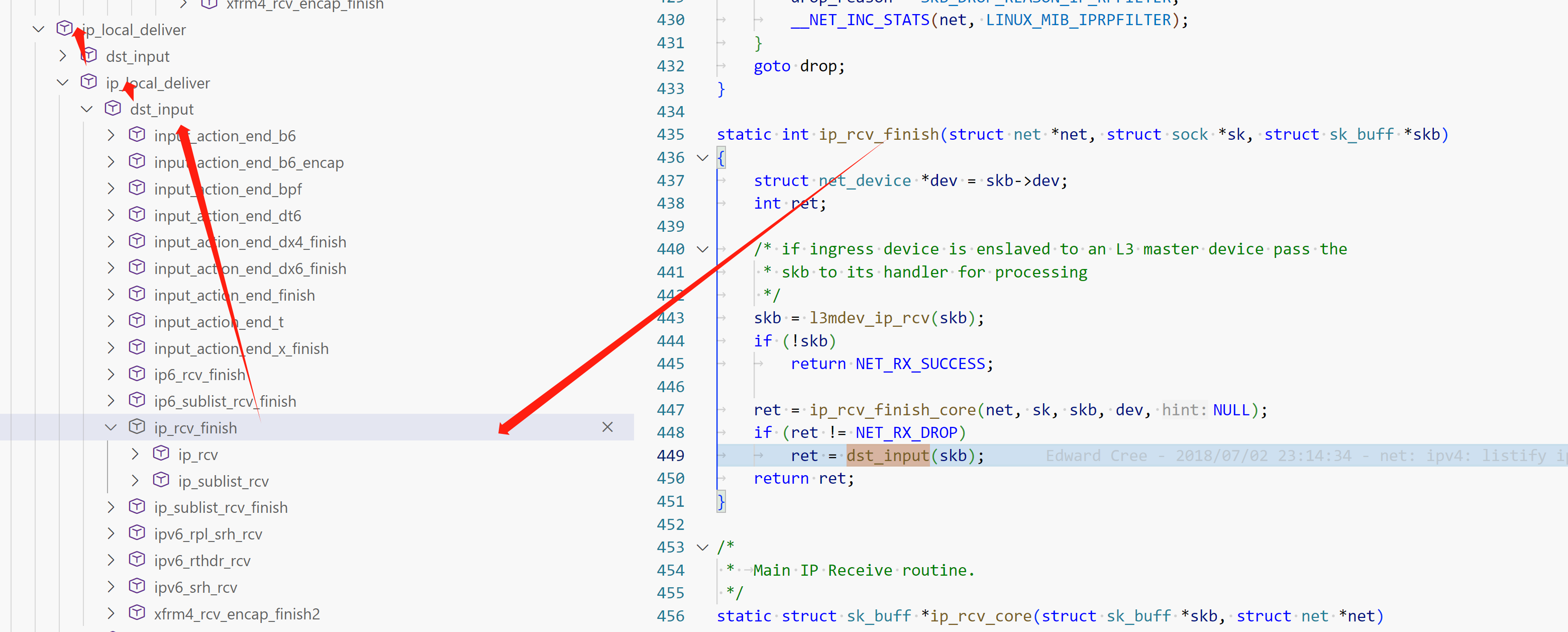
ip_rcv_finish
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 static int ip_rcv_finish (struct net *net, struct sock *sk, struct sk_buff *skb) { struct net_device *dev = int ret; skb = l3mdev_ip_rcv(skb); if (!skb) return NET_RX_SUCCESS; ret = ip_rcv_finish_core(net, sk, skb, dev, NULL ); if (ret != NET_RX_DROP) ret = dst_input(skb); return ret; }
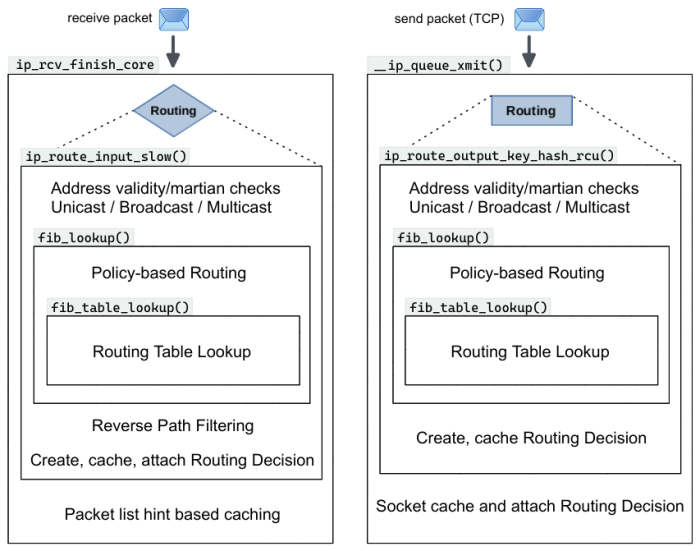
ip_rcv_finish_core: 查路由表,详细路由查询在 路由选择 ip_route_input_slow
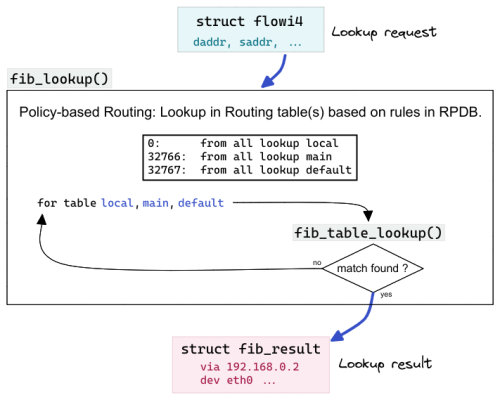
单就路由而言,路由是根据目的地IP进行选择的过程。而 PBR(policy-based routing)的引入使得路由结果还受 source ip address, skb->mark, tcp/udp source/destination port 等变量影响。struct flowi4 包含了上述可以被参考的字段值。
struct flowi4fib_lookup/fib_table_lookup 需 struct flowi4 和 struct fib_result 参数。
初始化 struct flowi4:给PBR提供除 destination ip 之外的参考信息
struct fib_result:fib_lookup 的 in_out 返回结果。ip_mkroute_input :根据 fib_lookup 返回的 struct fib_result 构造route cache
调用fib_lookup
路由选择
路由选择总览
fib(forwarding information base)IP_MULTIPLE_TABLES 选项。关闭则只有一张main表
使用如下 fib_lookup 函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 static inline int fib_lookup (struct net *net, const struct flowi4 *flp, struct fib_result *res, unsigned int flags) { struct fib_table *tb ; int err = -ENETUNREACH; rcu_read_lock(); tb = fib_get_table(net, RT_TABLE_MAIN); if (tb) err = fib_table_lookup(tb, flp, res, flags | FIB_LOOKUP_NOREF); if (err == -EAGAIN) err = -ENETUNREACH; rcu_read_unlock(); return err; }
开启则引入多路由表,代码如下
fib_lookup
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 static inline int fib_lookup (struct net *net, struct flowi4 *flp, struct fib_result *res, unsigned int flags) { struct fib_table *tb ; int err = -ENETUNREACH; flags |= FIB_LOOKUP_NOREF; if (net->ipv4.fib_has_custom_rules) return __fib_lookup(net, flp, res, flags); rcu_read_lock(); res->tclassid = 0 ; tb = rcu_dereference_rtnl(net->ipv4.fib_main); if (tb) err = fib_table_lookup(tb, flp, res, flags); if (!err) goto out; tb = rcu_dereference_rtnl(net->ipv4.fib_default); if (tb) err = fib_table_lookup(tb, flp, res, flags); out: if (err == -EAGAIN) err = -ENETUNREACH; rcu_read_unlock(); return err; }
使用 ip rule 列出/添加/删除 PBR
1 2 3 4 5 6 7 8 9 $ ip rule list # PRIORITY SELECTOR ACTION 0: from 127.0.0.1 iif lo ipproto tcp lookup 127 0: from 127.0.0.1 iif lo ipproto udp lookup 127 0: from all iif lo ipproto tcp lookup 128 0: from all iif lo ipproto udp lookup 128 0: from all lookup local 32766: from all lookup main 32767: from all lookup default
每个规则包含三部分,优先级,选择器,执行结果。优先级从小到大是规则被匹配的顺序。选择器匹配包信息,ACTION 执行具体的操作。
from all:任意source ip数据包都命中,执行action
lookup local: 到local表继续查找lookup main: 到main表继续查找lookup default: 到default表继续查找fib_lookup 的表查找顺序
如果 ip rule 过程有一条规则命中,查找马上停止,并使用此规则作为最后的路由规则。
fib_lookup__fib_lookup
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 int fib_table_lookup (struct fib_table *tb, const struct flowi4 *flp, struct fib_result *res, int fib_flags) { for (;;) { } for (;;) { } found: }
struct rtable
代表一条路由规则,路由结束绑定到skb#_skb_refdst
struct dst_entry dst_u16 rt_type
本路由类型
字段
值
ip route
含义
RTN_UNICAST1
unicast默认值,如果skb#_skb_refdst是此值,数据需要被转发
RTN_LOCAL2
local本机路由
RNT_BROADCAST3
广播
需要转发
RTN_MULTICAST5
多播
多播
RNT_UNREACHABLE7
unreachable丢弃,返回 ICMP network unreachable
__u8 rt_uses_gateway
bool,路由的下一跳是网关(ip route 返回类似 via 10.0.0.1 的格式),那么rt_gw4包含网关IP地址。
u8 rt_gw_family
如果 rt_uses_gateway 是0,那 rt_gw_family 是0。如果网关地址是IPV4,=AF_INET。IPV6, =AF_INET6
union {__be32 rt_gw4; struct in6_addr rt_gw6;}
如果是网关,根据IP类型使用 rt_gw4 或 rt_gw6 字段
struct dst_entry
struct net_device *dev
struct xfrm_state *xfrm
int (_input)(struct sk_buff_skb)
int (_output)(struct net_net, struct sock _sk, struct sk_buff_skb);
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 int ip_local_deliver (struct sk_buff *skb) { struct net *net = if (ip_is_fragment(ip_hdr(skb))) { if (ip_defrag(net, skb, IP_DEFRAG_LOCAL_DELIVER)) return 0 ; } return NF_HOOK(NFPROTO_IPV4, NF_INET_LOCAL_IN, net, NULL , skb, skb->dev, NULL , ip_local_deliver_finish); }
尝试重组skb。如果此skb分片包的最后一个那么ip_defrag返回0,获得完成的ip数据包。
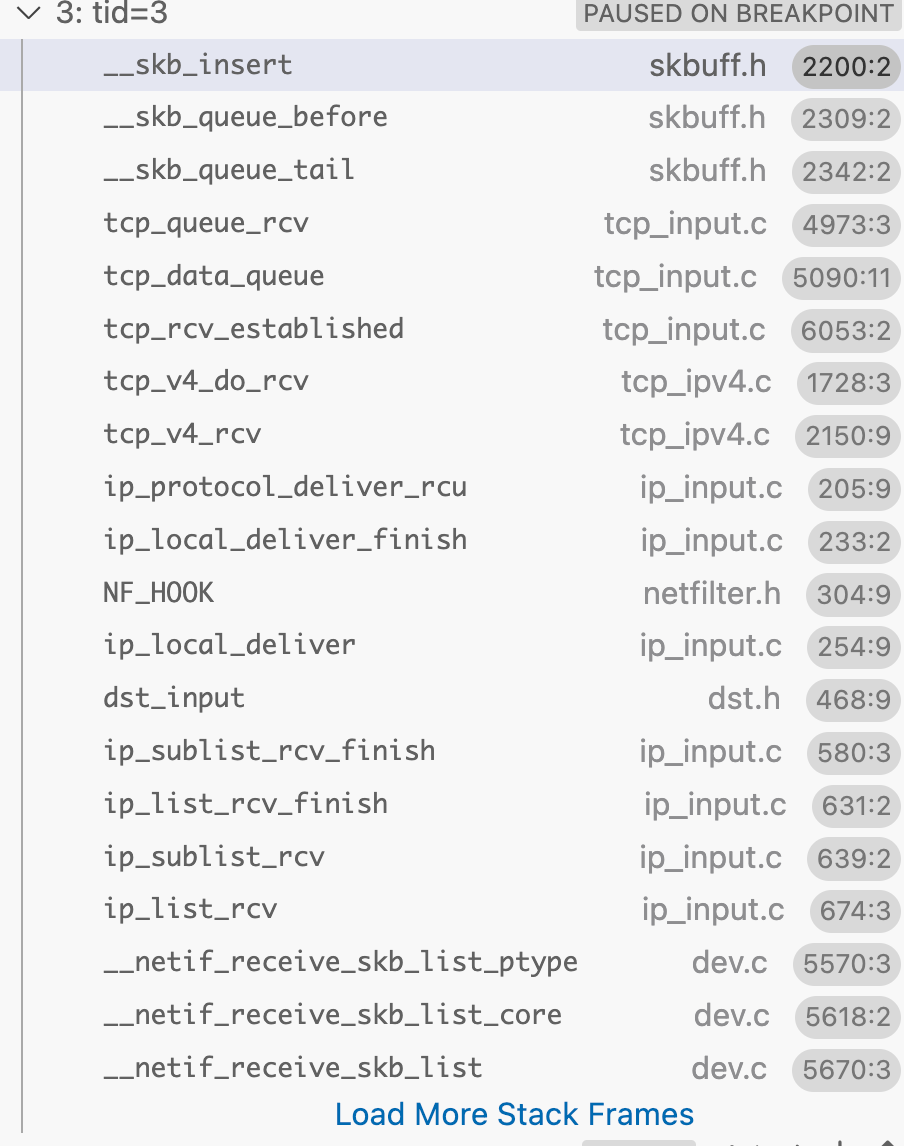
ip_local_deliver call stack
dst_input 是很薄的中间函数
1 2 3 4 5 static inline int dst_input (struct sk_buff *skb) { return INDIRECT_CALL_INET(skb_dst(skb)->input, ip6_input, ip_local_deliver, skb); }
展开 INDIRECT_CALL_INET
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 #define INDIRECT_CALL_INET(f, f2, f1, ...) \ INDIRECT_CALL_2(f, f2, f1, __VA_ARGS__) ({ __builtin_expect(!!(skb_dst(skb)->input == ip6_input), 1 ) ? ip6_input(skb) : ({ __builtin_expect(!!(skb_dst(skb)->input == ip_local_deliver), 1 ) ? ip_local_deliver(skb) : skb_dst(skb)->input(skb); }); })
如果 input 不等于 ip_local_deliver ,调用 skb_dst(skb)->input(skb);,否则调用 ip_local_deliver
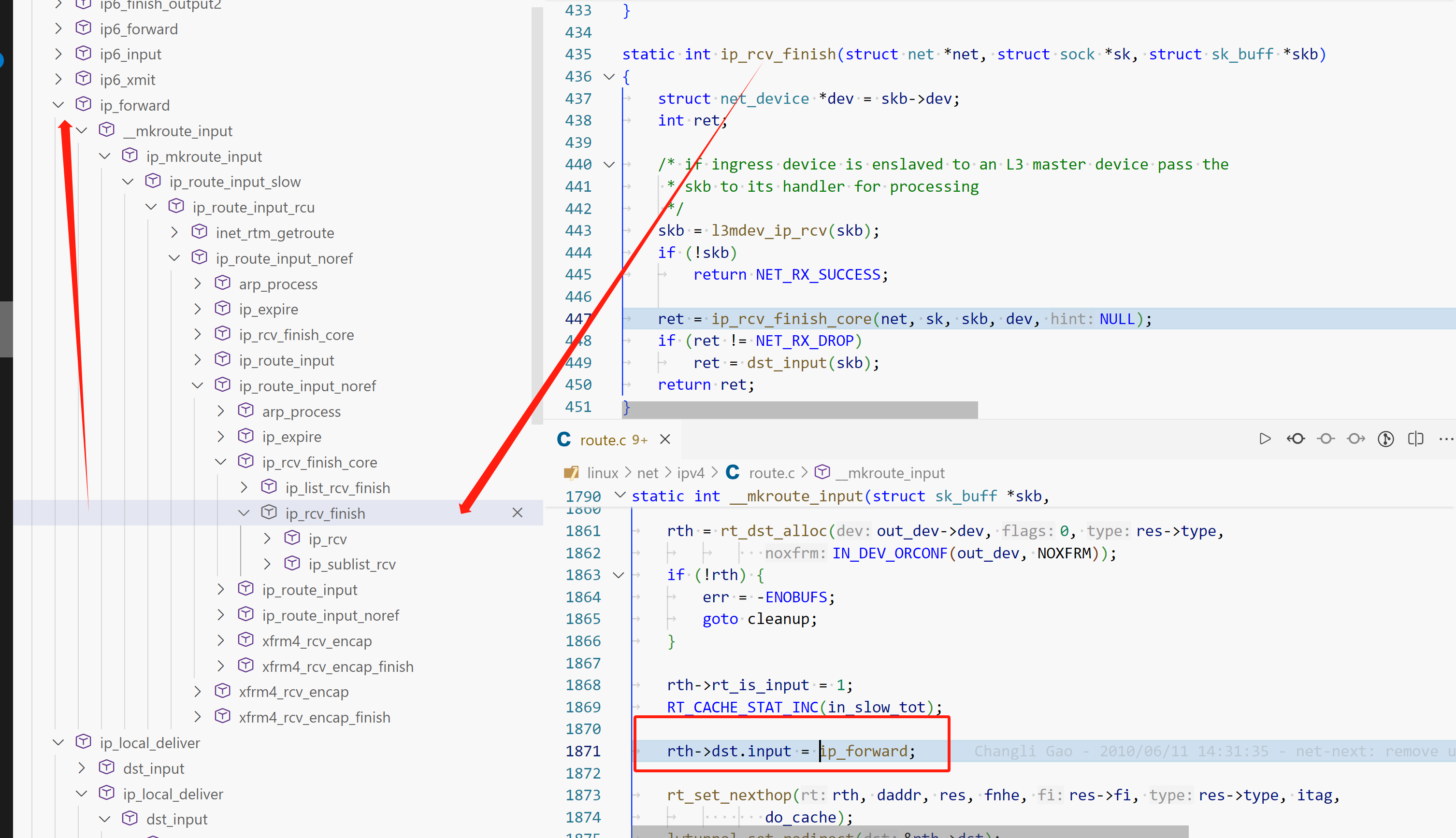
这样就包含多条路径,这些路径的 input 都在路由选择阶段赋值。ip_forward 说明数据包需要转发到本机外
ip_forward
ip forward 调用栈
ip_forwardnetfilter forward hook
1 2 3 4 5 6 int ip_forward (struct sk_buff *skb) { return NF_HOOK(NFPROTO_IPV4, NF_INET_FORWARD, net, NULL , skb, skb->dev, rt->dst.dev, ip_forward_finish); }
ip_forward_finish
dst_outputip_output
ip_output: 利用IP协议发送xfrm4_output: IPsec送达ip_mc_output: multicast packets
1 2 3 4 5 6 7 static inline int dst_output (struct net *net, struct sock *sk, struct sk_buff *skb) { return INDIRECT_CALL_INET(skb_dst(skb)->output, ip6_output, ip_output, net, sk, skb); }
ip_output
执行 Netfilter POSTROUTING HOOK
1 2 3 4 5 6 7 8 9 10 11 int ip_output (struct net *net, struct sock *sk, struct sk_buff *skb) { struct net_device *dev = skb->dev = dev; skb->protocol = htons(ETH_P_IP); return NF_HOOK_COND(NFPROTO_IPV4, NF_INET_POST_ROUTING, net, sk, skb, indev, dev, ip_finish_output, !(IPCB(skb)->flags & IPSKB_REROUTED)); }
ip_finish_output__ip_finish_outputip_finish_output2
进入netghbouring subsystem ,查找ARP cache,找到链路层 MAC
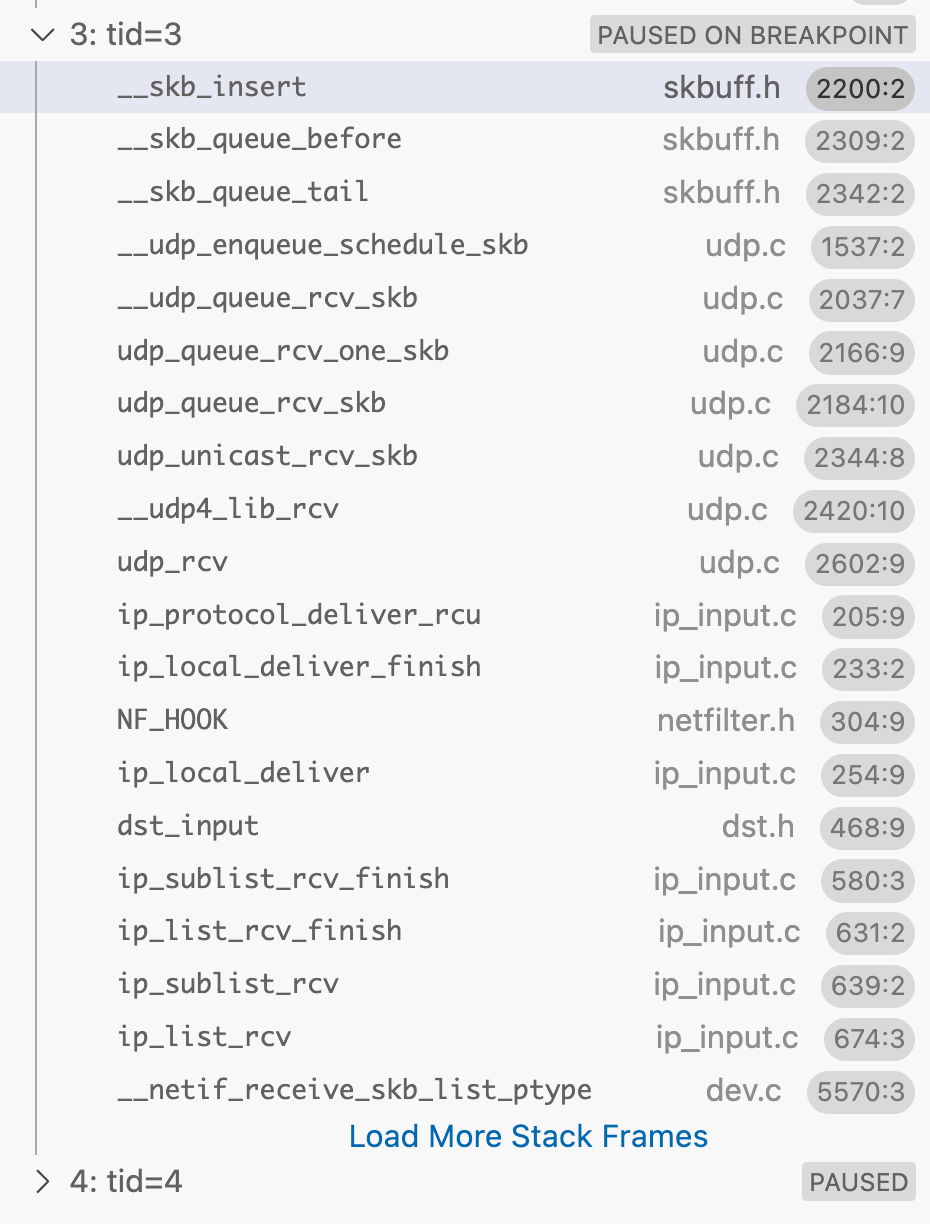
ip_local_deliver
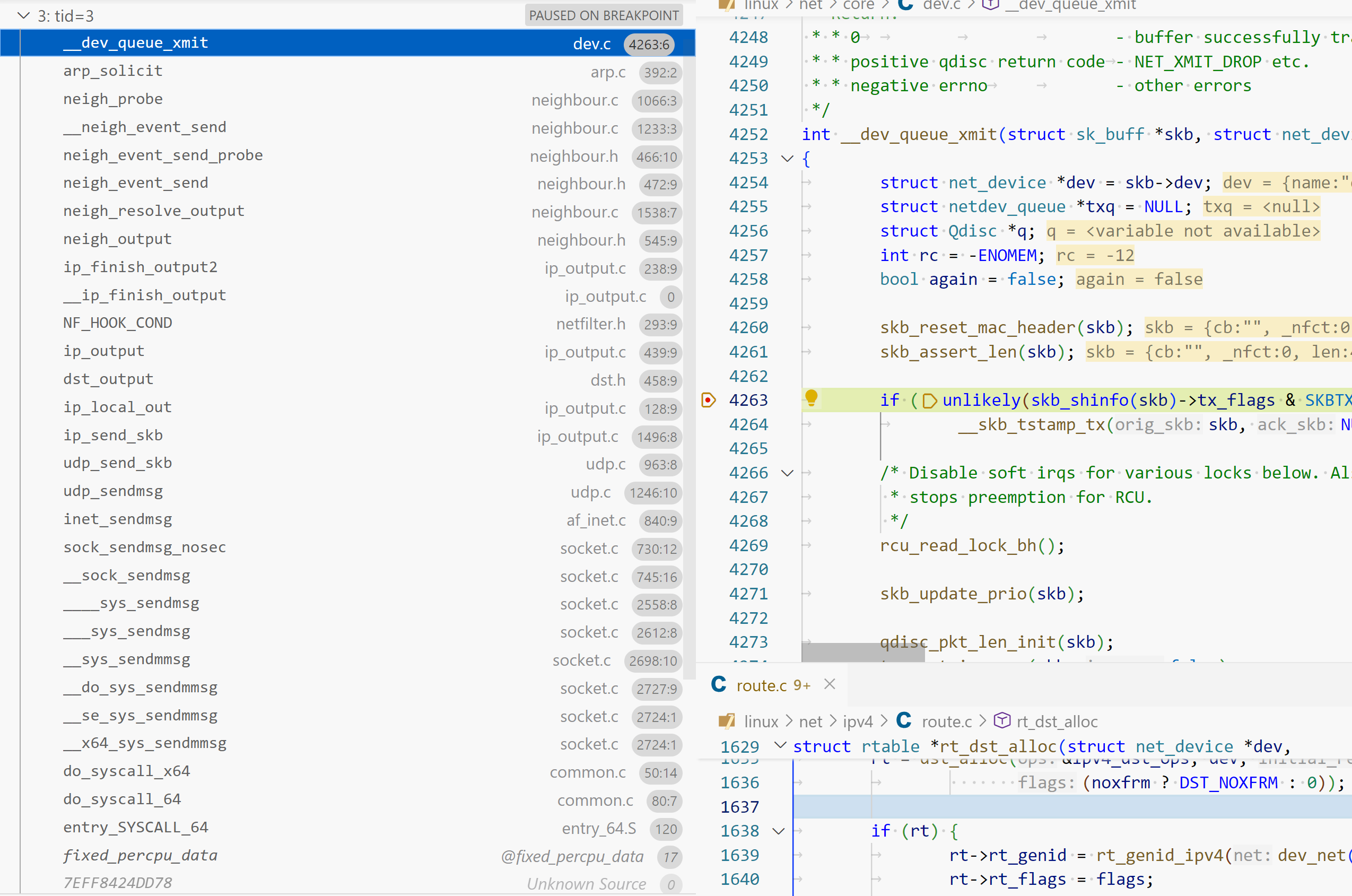
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 struct rtable *rt_dst_alloc (struct net_device *dev, unsigned int flags, u16 type, bool noxfrm) { struct rtable *rt ; rt = dst_alloc(&ipv4_dst_ops, dev, 1 , DST_OBSOLETE_FORCE_CHK, (noxfrm ? DST_NOXFRM : 0 )); if (rt) { rt->rt_genid = rt_genid_ipv4(dev_net(dev)); rt->rt_flags = flags; rt->rt_type = type; rt->rt_is_input = 0 ; rt->rt_iif = 0 ; rt->rt_pmtu = 0 ; rt->rt_mtu_locked = 0 ; rt->rt_uses_gateway = 0 ; rt->rt_gw_family = 0 ; rt->rt_gw4 = 0 ; rt->dst.output = ip_output; if (flags & RTCF_LOCAL) rt->dst.input = ip_local_deliver; } return rt; }
ip_local_deliver 在创建 dst_entry时初始化。如果ip packet目的地为本机,继续传递到上层协议栈
假设packet送往本机,分析 ip_local_deliver
继续调用
ip_local_deliver
ip_local_deliver_finiship_protocol_deliver_rcu
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 void ip_protocol_deliver_rcu (struct net *net, struct sk_buff *skb, int protocol) { const struct net_protocol *ipprot ; int raw, ret; resubmit: raw = raw_local_deliver(skb, protocol); ipprot = rcu_dereference(inet_protos[protocol]); if (ipprot) { if (!ipprot->no_policy) { if (!xfrm4_policy_check(NULL , XFRM_POLICY_IN, skb)) { kfree_skb_reason(skb, SKB_DROP_REASON_XFRM_POLICY); return ; } nf_reset_ct(skb); } ret = INDIRECT_CALL_2(ipprot->handler, tcp_v4_rcv, udp_rcv, skb); if (ret < 0 ) { protocol = -ret; goto resubmit; } __IP_INC_STATS(net, IPSTATS_MIB_INDELIVERS); } else { if (!raw) { if (xfrm4_policy_check(NULL , XFRM_POLICY_IN, skb)) { __IP_INC_STATS(net, IPSTATS_MIB_INUNKNOWNPROTOS); icmp_send(skb, ICMP_DEST_UNREACH, ICMP_PROT_UNREACH, 0 ); } kfree_skb_reason(skb, SKB_DROP_REASON_IP_NOPROTO); } else { __IP_INC_STATS(net, IPSTATS_MIB_INDELIVERS); consume_skb(skb); } } }
传输层
tcp_ipv4.c
1 2 3 4 5 6 7 static const struct net_protocol tcp_protocol = .handler = tcp_v4_rcv, .err_handler = tcp_v4_err, .no_policy = 1 , .icmp_strict_tag_validation = 1 , };
注册 tcp 回调,IP层根据protocol type回调传输层handler
udp send
udp receive
UDP sock receive
tcp send
tcp connect
tcp sendmsg
tcp receive
tcp rev + tcp syn send
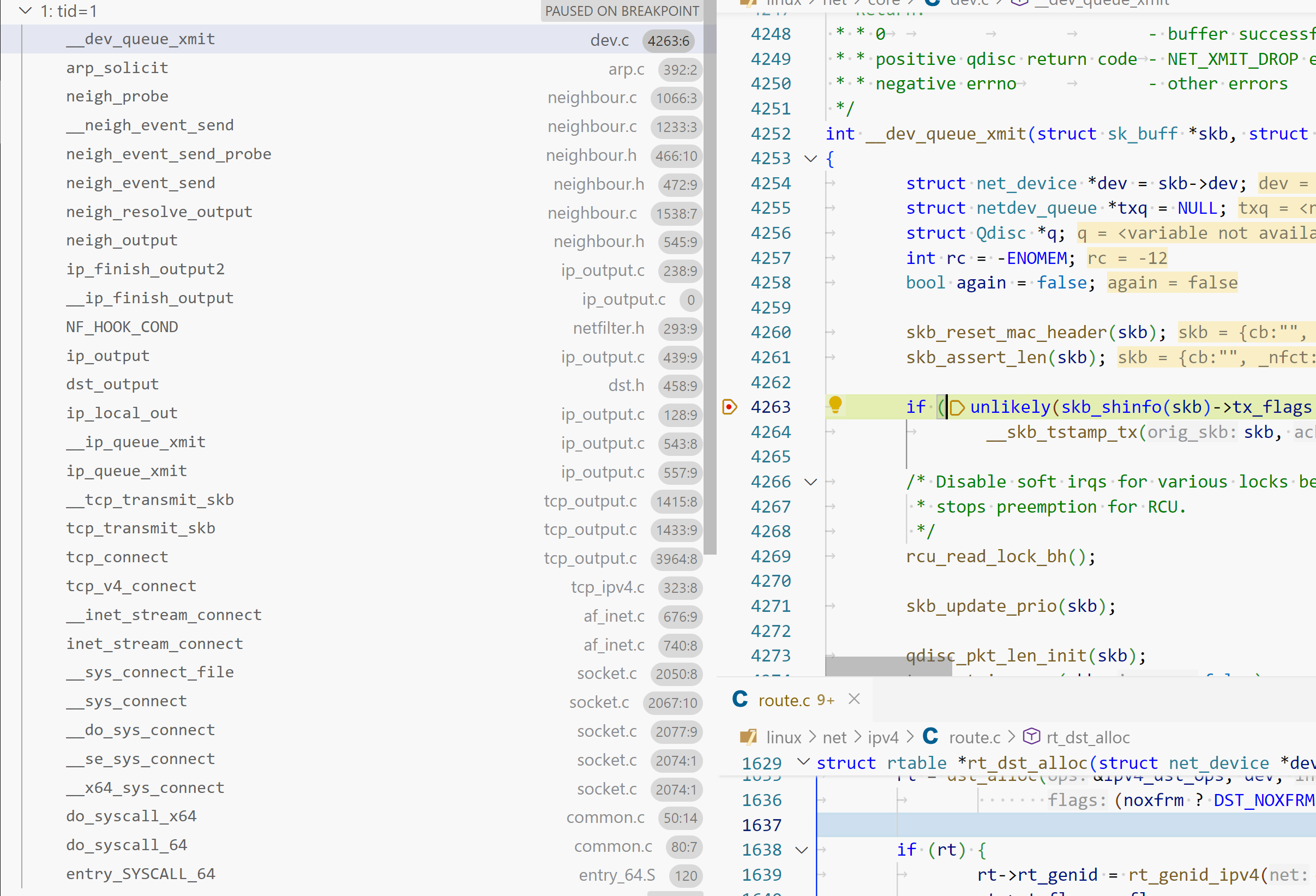
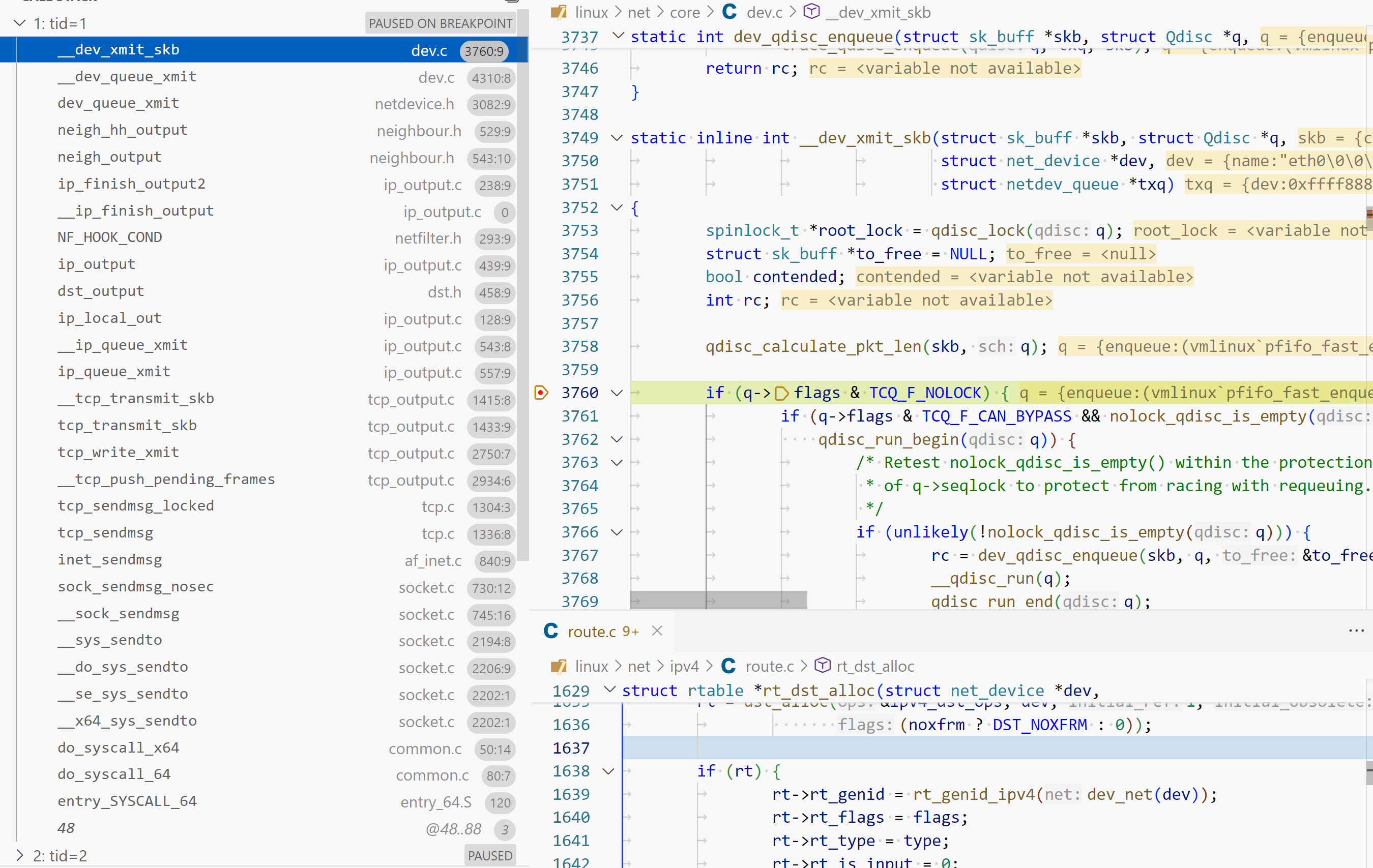
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 __dev_xmit_skb (\root\codes\kernel-dev\linux\net\core\dev.c:3760) __dev_queue_xmit (\root\codes\kernel-dev\linux\net\core\dev.c:4310) dev_queue_xmit (\root\codes\kernel-dev\linux\include\linux\netdevice.h:3082) neigh_hh_output (\root\codes\kernel-dev\linux\include\net\neighbour.h:529) neigh_output (\root\codes\kernel-dev\linux\include\net\neighbour.h:543) ip_finish_output2 (\root\codes\kernel-dev\linux\net\ipv4\ip_output.c:238) __ip_finish_output (\root\codes\kernel-dev\linux\net\ipv4\ip_output.c:0) NF_HOOK_COND (\root\codes\kernel-dev\linux\include\linux\netfilter.h:293) ip_output (\root\codes\kernel-dev\linux\net\ipv4\ip_output.c:439) dst_output (\root\codes\kernel-dev\linux\include\net\dst.h:458) ip_local_out (\root\codes\kernel-dev\linux\net\ipv4\ip_output.c:128) __ip_queue_xmit (\root\codes\kernel-dev\linux\net\ipv4\ip_output.c:543) ip_queue_xmit (\root\codes\kernel-dev\linux\net\ipv4\ip_output.c:557) __tcp_transmit_skb (\root\codes\kernel-dev\linux\net\ipv4\tcp_output.c:1415) __tcp_send_ack (\root\codes\kernel-dev\linux\net\ipv4\tcp_output.c:4082) tcp_send_ack (\root\codes\kernel-dev\linux\net\ipv4\tcp_output.c:4088) tcp_rcv_synsent_state_process (\root\codes\kernel-dev\linux\net\ipv4\tcp_input.c:6363) tcp_rcv_state_process (\root\codes\kernel-dev\linux\net\ipv4\tcp_input.c:6539) tcp_v4_do_rcv (\root\codes\kernel-dev\linux\net\ipv4\tcp_ipv4.c:1751) tcp_v4_rcv (\root\codes\kernel-dev\linux\net\ipv4\tcp_ipv4.c:2150) ip_protocol_deliver_rcu (\root\codes\kernel-dev\linux\net\ipv4\ip_input.c:205) ip_local_deliver_finish (\root\codes\kernel-dev\linux\net\ipv4\ip_input.c:233) NF_HOOK (\root\codes\kernel-dev\linux\include\linux\netfilter.h:304) ip_local_deliver (\root\codes\kernel-dev\linux\net\ipv4\ip_input.c:254) dst_input (\root\codes\kernel-dev\linux\include\net\dst.h:468) ip_sublist_rcv_finish (\root\codes\kernel-dev\linux\net\ipv4\ip_input.c:580) ip_list_rcv_finish (\root\codes\kernel-dev\linux\net\ipv4\ip_input.c:631) ip_sublist_rcv (\root\codes\kernel-dev\linux\net\ipv4\ip_input.c:639) ip_list_rcv (\root\codes\kernel-dev\linux\net\ipv4\ip_input.c:674) __netif_receive_skb_list_ptype (\root\codes\kernel-dev\linux\net\core\dev.c:5570) __netif_receive_skb_list_core (\root\codes\kernel-dev\linux\net\core\dev.c:5618) __netif_receive_skb_list (\root\codes\kernel-dev\linux\net\core\dev.c:5670) netif_receive_skb_list_internal (\root\codes\kernel-dev\linux\net\core\dev.c:5761) gro_normal_list (\root\codes\kernel-dev\linux\include\net\gro.h:439) napi_complete_done (\root\codes\kernel-dev\linux\net\core\dev.c:6101) e1000_clean (\root\codes\kernel-dev\linux\drivers\net\ethernet\intel\e1000\e1000_main.c:3811) __napi_poll (\root\codes\kernel-dev\linux\net\core\dev.c:6531) napi_poll (\root\codes\kernel-dev\linux\net\core\dev.c:6598) net_rx_action (\root\codes\kernel-dev\linux\net\core\dev.c:6731) __do_softirq (\root\codes\kernel-dev\linux\kernel\softirq.c:553) invoke_softirq (\root\codes\kernel-dev\linux\kernel\softirq.c:427) __irq_exit_rcu (\root\codes\kernel-dev\linux\kernel\softirq.c:632) irq_exit_rcu (\root\codes\kernel-dev\linux\kernel\softirq.c:644) sysvec_apic_timer_interrupt (\root\codes\kernel-dev\linux\arch\x86\kernel\apic\apic.c:1074)
netfilter hook
入口点
1 2 3 4 5 6 7 8 9 10 11 static inline int NF_HOOK (uint8_t pf, unsigned int hook, struct net *net, struct sock *sk, struct sk_buff *skb, struct net_device *in, struct net_device *out, int (*okfn)(struct net *, struct sock *, struct sk_buff *)) { int ret = nf_hook(pf, hook, net, sk, skb, in, out, okfn); if (ret == 1 ) ret = okfn(net, sk, skb); return ret; }
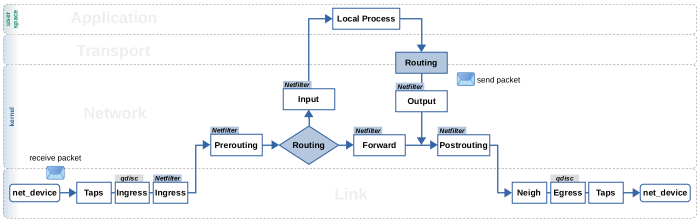
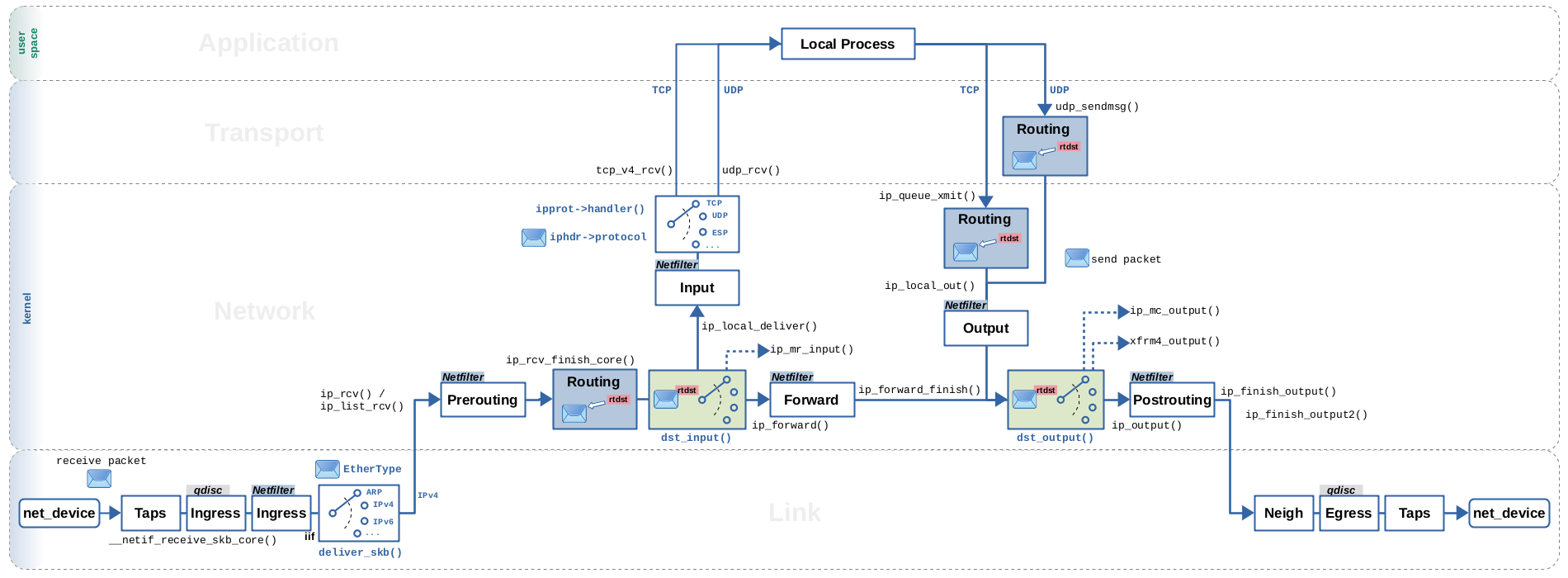
数据包流
通常在协议栈有很多的决策点,根据不同的条件调用C的各种函数回调,将包送到不同的路径。
绿色部分是和路由相关的两个分流点。
dst_input: 根据routing结果决定packet是local还是forward
dst_output: 根据skb_dst(skb)->output不同值,决定如何调用三层协议发送
1 2 3 4 5 6 static inline int dst_output (struct net *net, struct sock *sk, struct sk_buff *skb) { return INDIRECT_CALL_INET(skb_dst(skb)->output, ip6_output, ip_output, net, sk, skb);
下图还针对收包展示了两个分流点。
deliver_skb: 根据链路层Type字段区分三层协议,IPv4, IPv6, ARP等等。如果三层是IP协议,通过iphdr->protocol字段区分传输层协议TCP,UDP回调handler
1 2 ret = INDIRECT_CALL_2(ipprot->handler, tcp_v4_rcv, udp_rcv, skb);
追踪skb->_skb_refdst代表的 dst_entry * 结构变化,展示packet收到后的处理流程
从图的左下角看起
数据包可以一个个处理
__netif_receive_skb -> deliver_skb
也可以作为lists一同处理
__netif_receive_skb_list -> netif_receive_skb_list_ptype
两种处理方式最后都回调上层 non-list 或者 list 的 handler
ipv4 的 handler 在init阶段注册inet_init
1 2 3 4 5 ipfrag_init(); dev_add_pack(&ip_packet_type); ip_tunnel_core_init();
协议分发利用EtherType - Wikipedia 字段,通过hashtable查找handle,ipv4的两个回调函数分别为 ip_rcv和 ip_list_rcv。
一到达网络层,首先进行 Netfilter Prerouting ,如果没有被丢弃,继续调用
ip_rcv_finish/ip_list_rcv_finiship_rcv_finish_core
参考
Routing Decisions in the Linux Kernel - Part 1: Lookup and packet flow networking:kernel_flow [Wiki] Linux 网络栈接收数据(RX):原理及内核实现(2022)